Sequential Monte Carlo (SMC) methods are usually designed to deal with probability distributions of increasing dimensions. The canonical example is the sequence of distributions 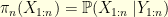 where
where 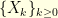 is a hidden Markov chain and
is a hidden Markov chain and 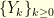 is an observation process. The notation
is an observation process. The notation 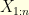 is a shortcut for
is a shortcut for 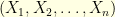 . This is usually called a Hidden Markov Model in the literature. If the Markov chain
. This is usually called a Hidden Markov Model in the literature. If the Markov chain 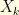 evolves on in
evolves on in 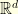 then the distribution
then the distribution  is a probability on
is a probability on 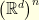 .
.

It turns out that one can use the same kind of ideas to study a single distribution 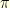 . If is difficult to sample directly from and that it is difficult to use traditional MCMC methods (because of the dimensionality, multi-modality, poor mixing properties, etc…), one can try to use SMC methods to study the distribution . To this end, one can introduce a sequence of bridging distributions
. If is difficult to sample directly from and that it is difficult to use traditional MCMC methods (because of the dimensionality, multi-modality, poor mixing properties, etc…), one can try to use SMC methods to study the distribution . To this end, one can introduce a sequence of bridging distributions
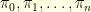
where 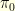 is typically very easy to sample from and
is typically very easy to sample from and 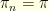 . A traditional choice is
. A traditional choice is 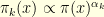 where
where 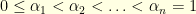 . The bigger the index
. The bigger the index 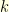 , the more intricate the distribution
, the more intricate the distribution 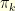 is. The problem is that each distribution has the same dimensionality as the original distribution so that it is difficult to use all the machinery of SMC methods. For the sake of concreteness, let us suppose that is a distribution on . A fundamental remark that is the base of what is now known as Sequential Monte Carlo samplers is that
is. The problem is that each distribution has the same dimensionality as the original distribution so that it is difficult to use all the machinery of SMC methods. For the sake of concreteness, let us suppose that is a distribution on . A fundamental remark that is the base of what is now known as Sequential Monte Carlo samplers is that 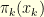 can be seen as the marginal distribution of the probability
can be seen as the marginal distribution of the probability

where  are Markov kernels in the sense that for any
are Markov kernels in the sense that for any  we have
we have 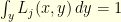 . The distribution
. The distribution 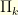 lives on
lives on  and one can use the traditional SMC methods to explore the sequence of distributions
and one can use the traditional SMC methods to explore the sequence of distributions 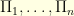 . This algorithm was devised a few years ago by Pierre Del Moral, Arnaud Doucet and Ajay Jasra. It is extremely powerful and several other algorithms can be seen as particular cases of it. Because I had never implemented the algorithm before, I tried yesterday to see how this worked on a very simple example. My target distribution was an equal mixture of seven Gaussian distributions in
. This algorithm was devised a few years ago by Pierre Del Moral, Arnaud Doucet and Ajay Jasra. It is extremely powerful and several other algorithms can be seen as particular cases of it. Because I had never implemented the algorithm before, I tried yesterday to see how this worked on a very simple example. My target distribution was an equal mixture of seven Gaussian distributions in  with unit covariance matrices and centred at the vertices of a regular heptagon with radius
with unit covariance matrices and centred at the vertices of a regular heptagon with radius 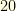 . I started with
. I started with 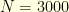 particles at the centre of the heptagon and let them evolved according to a random walk. When the Effective Sampling Size (ESS) was too small (less than
particles at the centre of the heptagon and let them evolved according to a random walk. When the Effective Sampling Size (ESS) was too small (less than 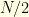 ), the whole particle system was regenerated. In order to obtain a sweet movie, I used
), the whole particle system was regenerated. In order to obtain a sweet movie, I used 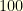 bridge distributions
bridge distributions 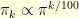 .
.

The result is clear and quite impressive. Indeed, this could have been made much more efficient by taking much less bridge distributions. Some recent theory has been developed to analyse the stability of the algorithm in high dimensional situations. The analysis described in the article uses a scaling limit approach very similar to some ideas used to analyse MCMC algorithms and some more recent developements along the same lines that we have done with Andrew and Natesh. Very exciting stuff!
[EDIT: 2 October 2012]
I received several emails asking me to describe how to obtain the short animation showing the evolution of the particles system. The code is available here. This is a quick python script producing a bunch of .png files. It then suffices to stick them together to obtain an animated .gif file. This can for example easily be done using the free (and very good) photoshop-like software GIMP. Open all the png files as different layers. Export the result as a .gif file with the option ‘animated gif’ checked. Voila!



